An open forward-compatible instruction set architecture
ForwardCom is an experimental project for the development of a new open instruction set architecture and the corresponding open hardware and software standards for high performance microprocessors and vector processors. The purpose is to investigate what an ideal computer architecture may look like and to develop a complete open source and open license computer system that is more efficient than the currently prevailing systems, such as x86, ARM, etc.
ForwardCom is used as a sandbox for experimenting with various ways of improving performance when we are not constrained by the need for compatibility with existing hardware and software.
ForwardCom is also useful as a high-end alternative to RISC-V and other open hardware architectures. Starting from scratch and making a complete vertical redesign of the hardware-software ecosystem allows us to learn from the history of past mistakes and get rid of the heritage of old quirks that hamper contemporary computer systems.
Common RISC designs have a serious limitation in the instruction size. Typically, the instruction size is fixed at 32 bits. This limits the amount of information that can be contained in a single RISC instruction. For example, you need multiple RISC instructions for loading a 32-bit constant or a 32-bit address. You cannot have more than one or a few variants of each instruction because there are not enough bits in the code word to indicate the different variants. Instead, you must use multiple operation codes (opcodes) if you want multiple variants of an instruction.
The most popular CISC design is the x86 instruction set with its many extensions. The CISC instruction set typically has many opcodes for different variants of the same instruction. In fact, there are now more than two thousand different opcodes in the x86 instruction set if you include all the extensions. Decoding x86 instructions is very complicated and a serious bottleneck.
The ForwardCom instruction set is designed to overcome the problems of both RISC and CISC. ForwardCom instructions can have a size of one, two, or three 32-bit words. The length of each instruction is specified by just two bits in the first code word. This makes it possible to decode multiple instructions per clock cycle without the need for a micro-operations cache. Decoding is simple because all instructions fit into the same standardized template system.
Most ForwardCom instructions can be coded in several different formats. This includes compact instructions with a single-word size, as well as double and triple size versions when there is a need for more registers, bigger constant operands, bigger memory addresses, or additional option bits. Common instructions have many different variants with different types of registers, different precisions, constant operands with different sizes, memory operands with different addressing modes, predicate masks for conditional execution, and extra option bits for sign change or other extra features.
It is more efficient to have many different variants of the same instruction than to have different instructions or opcodes for each variant. This makes the hardware simpler because the variants are coded in the same consistent way for all instructions. It also makes the code more efficient because it can do more work per instruction. It is possible to define complex instructions that do multiple things, but only as long as they fit into a standardized template system, pipeline structure, and timing restrictions. This makes sure that even quite complex instructions that are doing multiple things can execute at a speed of one instruction per clock cycle per hardware pipeline. This system is further explained here.
The ForwardCom instruction set is based on a consistent and flexible modular format suitable for fast superscalar processors. Each instruction uses one, two, or three 32-bit words. The bigger formats are used if large constants, large memory addresses, complex addressing modes, or extra option bits are needed. The assembler will automatically select the smallest possible instruction format that fits the specified operands. This template system is further explained here.
Vector registers are used for handling multiple data simultaneously. The advanced computers that are commonly used today have vector registers with fixed lengths. Every time a new CPU model with longer vectors comes on the market, the software has to be recompiled using a new instruction set extension that supports the new vector size. Software developers have to develop a new version of their software every time a new CPU model comes on the market, and they have to maintain and support several different versions of their software for the different CPU models if they want to use all CPU models optimally. This is so expensive for software developers that it is hardly ever done. Most of the software that is sold today is optimized for CPU models that are already obsolete.
A further problem with traditional designs is that it is impossible to make the software save a vector register in a way that will be compatible with future extensions of the vector length, because the instructions for doing so have not yet been defined.
The need to solve these problems was a strong motivation for developing ForwardCom. The ForwardCom architecture has variable-length vector registers. The software can use the maximum vector length supported by the CPU it is running on, or it can specify any vector length less than this. The length of a vector register is stored in the register itself. This is useful when a vector register is saved to memory and you do not want to save more data than the register actually contains.
The variable-length vector registers can be used in a new and very efficient type of loops that automatically uses the maximum vector length, even if this vector length was not supported at the time the software was written. This is what we call forward compatibility.
Let us consider a simple loop that does something with an array of 10 floats. It may look something like this in C code:
float my_array[10];
for (int i = 0; i < 10; i++) {
do_something(my_array[i]);
}
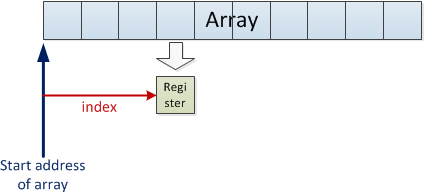
A simple implementation will use i as an index relative to the start address of the array while counting i up to 10, and load one element at a time into a register:
|
A vector implementation in a traditional system will load a number of consecutive array elements, for example four, into a vector register and increment i by four for each iteration of the loop:
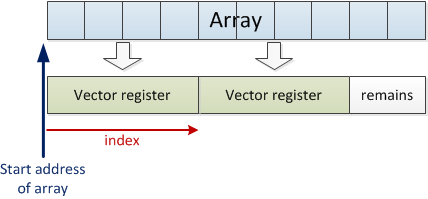 |
In this example, the loop will iterate two times and handle four array elements in each iteration. There are two remaining elements in the end because the length of the array is not divisible by the vector length. These remaining elements are handled separately outside the loop.
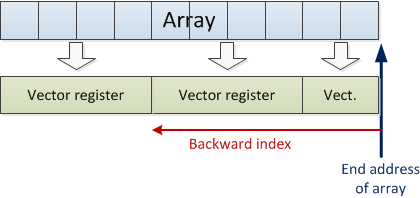
The ForwardCom system can code this loop in a more efficient way. We are using a backward index from the end of the array. The backward index counts down from 10 so that it always contains the remaining number of array elements to handle. The backward index is also used for specifying the desired vector length. If we ask for a longer vector than the CPU supports, then we will automatically get the maximum vector length. In this example the maximum length is four elements. In the first iteration we ask for ten elements and get four. The backward index is now decremented by four. In the next iteration we ask for six elements and get four. In the last iteration we ask for two elements and get two.
 |
This method has several advantages. First, we do not need any extra code to handle the remaining array elements if the array length is not divisible by the vector length. And second, it adjusts automatically to the maximum vector length of the CPU it is running on. If we run the same code on a CPU with a maximum vector length of 8 then the loop will run two iterations, handling 8 elements in the first iteration and 2 elements in the second iteration. If the maximum vector length is 16 then the loop will run only one iteration with a vector length of 10 elements.
The ForwardCom instruction set has a special addressing mode to support this loop method. The special addressing mode has a memory operand with a pointer register containing the end address, and a backward index register that is subtracted from this pointer. A vector memory operand always uses an extra register to specify the length of the vector. Here, we are using the same register for backward index and vector length. This works because we will get the maximum vector length when the specified length is more than the maximum length.
The loop may contain function calls. Assume, for example, that the code in our example involves the calculation of the logarithm of each vector element. The logarithm function is contained in a standard math function library. Now, this function uses a vector register for input and a vector register for output. The information about the vector length is contained in the vector register itself. Therefore, the logarithm function can handle a vector of any length and calculate the logarithms of all vector elements simultaneously. A scalar (single element) parameter is simply handled by the function as a vector with one element. This makes it easy for an optimizing compiler to convert scalar code to vector code, even if the code contains function calls.
Security is an integral part of the hardware and software design. This includes the following features:
The security features are further described here.
The following development tools are currently available: High-level assembler, disassembler, linker, library manager, emulator, and debugger. These tools are described here. A compiler is not available yet.
A hardware implementation of a ForwardCom CPU is available as an FPGA softcore. The hardware description code is published with an open license. The current softcore model A supports only integer instructions. The softcore is described here.
ForwardCom will not readily replace the present commercial systems, even if it is better, because the users need compatibility with existing hardware and software. However, the development of an ideal instruction set architecture and a complete redesign of the ecosystem of hardware and software standards is a worthwhile exercise in itself which may produce useful results and unexpected new discoveries. This project has already generated so many valuable ideas that it is worth pursuing further.
Let us assume that the need for a new instruction set will arise in the future, for whatever reason. Then it will be good to have a ready proposal that has been through a long development process rather than starting from scratch with a limited time budget and end up with a suboptimal solution. An open ongoing development process with inputs from anybody interested is likely to generate better results than the usual closed industry process with its short-term commercial priorities.
ForwardCom may, for example, be useful for the following purposes:
ForwardCom will also be useful as a sandbox for university projects and experiments with new ideas such as:
The ForwardCom project is under continuous development.
The basic instruction set architecture has been designed and a complete set of application-level instructions is defined. Some system-level instructions are not fully developed yet.
The structure of the binary file format for object files, function libraries, and executable files has been defined in details.
The details of application binary interface standards (ABI), function calling convention, etc. have been defined.
A high-level assembly language has been developed.
The following binary tools have been developed: high-level assembler, disassembler, linker, library manager, emulator, and debugger.
A hardware implementation in an FPGA soft core is available with full documentation. The current version supports integer instructions only.
Website and manual: Creative commons, CC-BY.
Binary tools: Gnu general public license, GPLv3
Soft-core: CERN open hardware licence, CERN-OHL-W
By Agner Fog, 2017 - 2025.